Research Projects
Video Jigsaw: Unsupervised Learning of Spatiotemporal Context for Video Action Recognition
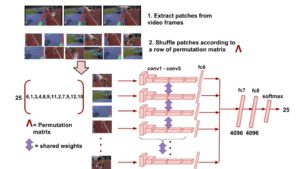 We propose a self-supervised learning method to jointly reason about spatial and temporal context for video recognition. Recent self-supervised approaches have used spatial context [9, 34] as well as temporal coherency [32] but a combination of the two requires extensive preprocessing such as tracking objects through millions of video frames [59] or computing optical flow to determine frame regions with high motion [30]. We propose to combine spatial and temporal context in one self-supervised framework without any heavy preprocessing. We divide multiple video frames into grids of patches and train a network to solve jigsaw puzzles on these patches from multiple frames. So the network is trained to correctly identify the position of a patch within a video frame as well as the position of a patch over time. We also propose a novel permutation strategy that outperforms random permutations while significantly reducing computational and memory constraints. We use our trained network for transfer learning tasks such as video activity recognition and demonstrate the strength of our approach on two benchmark video action recognition datasets without using a single frame from these datasets for unsupervised pretraining of our proposed video jigsaw network. [arXiv]
We propose a self-supervised learning method to jointly reason about spatial and temporal context for video recognition. Recent self-supervised approaches have used spatial context [9, 34] as well as temporal coherency [32] but a combination of the two requires extensive preprocessing such as tracking objects through millions of video frames [59] or computing optical flow to determine frame regions with high motion [30]. We propose to combine spatial and temporal context in one self-supervised framework without any heavy preprocessing. We divide multiple video frames into grids of patches and train a network to solve jigsaw puzzles on these patches from multiple frames. So the network is trained to correctly identify the position of a patch within a video frame as well as the position of a patch over time. We also propose a novel permutation strategy that outperforms random permutations while significantly reducing computational and memory constraints. We use our trained network for transfer learning tasks such as video activity recognition and demonstrate the strength of our approach on two benchmark video action recognition datasets without using a single frame from these datasets for unsupervised pretraining of our proposed video jigsaw network. [arXiv]
Semi-Supervised Action Recognition from Videos using Generative Adversarial Networks
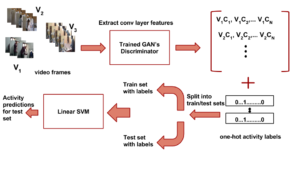
We propose an action recognition framework using Gen-erative Adversarial Networks. Our model involves train-ing a deep convolutional generative adversarial network (DCGAN) using a large video activity dataset without la-bel information. Then we use the trained discriminator from the GAN model as an unsupervised pre-training step and fine-tune the trained discriminator model on a labeled dataset to recognize human activities. We determine good network architectural and hyperparameter settings for us-ing the discriminator from DCGAN as a trained model to learn useful representations for action recognition. Our semi-supervised framework using only appearance infor-mation achieves superior or comparable performance to the current state-of-the-art semi-supervised action recog-nition methods on two challenging video activity datasets: UCF101 and HMDB51. [arXiv]
Social Event Recognition from Static Images
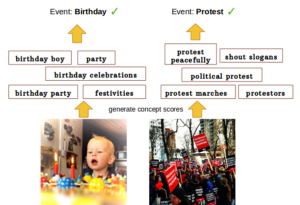
We propose to leverage concept-level representations for complex event recognition in photographs given limited training examples. We introduce a novel framework to discover event concept attributes from the web and use that to extract semantic features from images and classify them into social event categories with few training examples. Discovered concepts include a variety of objects, scenes, actions and event sub-types, leading to a discriminative and compact representation for event images. Web images are obtained for each discovered event concept and we use (pretrained) CNN features to train concept classifiers. Extensive experiments on challenging event datasets demonstrate that our proposed method outperforms several baselines using deep CNN features directly in classifying images into events with limited training examples. We also demonstrate that our method achieves the best overall accuracy on a dataset with unseen event categories using a single training example. [paper][project]
Towards Using Visual Attributes to Infer Image Sentiment Of Social Events
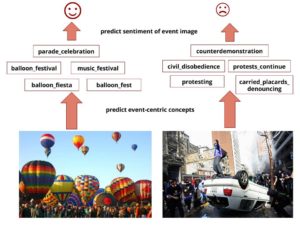 Widespread and pervasive adoption of smartphones has led to instant sharing of photographs that capture events ranging from mundane to life-altering happenings. We propose to capture sentiment information of such social event images leveraging their visual content. Our method extracts an intermediate visual representation of social event images based on the visual attributes that occur in the images going beyond
Widespread and pervasive adoption of smartphones has led to instant sharing of photographs that capture events ranging from mundane to life-altering happenings. We propose to capture sentiment information of such social event images leveraging their visual content. Our method extracts an intermediate visual representation of social event images based on the visual attributes that occur in the images going beyond
sentiment-specific attributes. We map the top predicted attributes to sentiments and extract the dominant emotion associated with a picture of a social event. Unlike recent approaches, our method generalizes to a variety of social events and even to unseen events, which are not available at training time. We demonstrate the effectiveness of our approach on a challenging social event image dataset and our method outperforms state-of-the-art approaches for classifying complex event images into sentiments. [paper][dataset]
Social Event Detection Using Kernel Canonical Correlation Analysis
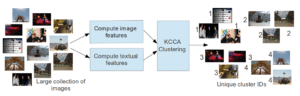
Sharing user experiences in the form of photographs, tweets, text, audio and/or video has become commonplace in social media. Browsing through uploaded content of a particular event remains cumbersome. It requires a user to initiate textual search query and manually go through a list of resulting images to find relevant information. We propose an automatic clustering algorithm, which given a large collection of images, groups them into a cluster of different events using the image features and the related metadata. We formulate this problem as a kernel canonical correlation clustering problem in which data samples from different modalities or ‘views’ are projected to a space where correlations between the samples’ projections are maximized. [poster]